|
Kaichun Mo, Leonidas J. Guibas, Mustafa Mukadam, Abhinav Gupta and Shubham Tulsiani, Where2Act: From Pixels to Actions for Articulated 3D Objects, International Conference on Computer Vision (ICCV) 2021
Abstract:
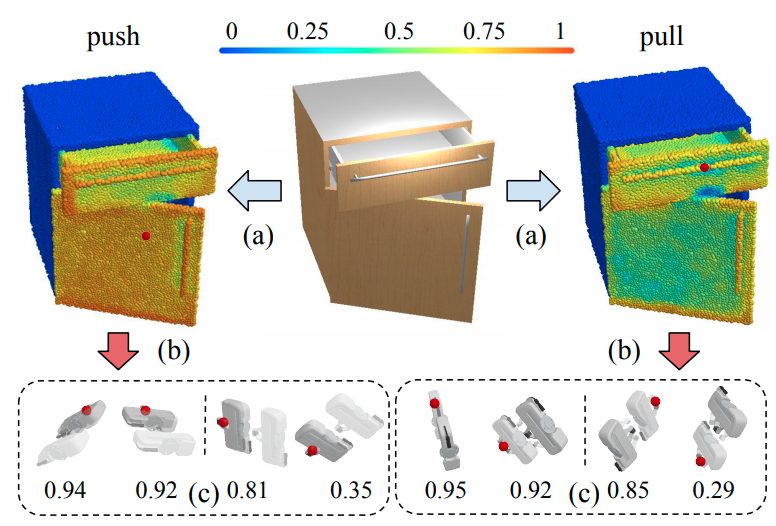
One of the fundamental goals of visual perception is to allow agents to meaningfully interact with their environment. In this paper, we take a step towards that long-term goal -- we extract highly localized actionable information related to elementary actions such as pushing or pulling for articulated objects with movable parts. For example, given a drawer, our network predicts that applying a pulling force on the handle opens the drawer. We propose, discuss, and evaluate novel network architectures that given image and depth data, predict the set of actions possible at each pixel, and the regions over articulated parts that are likely to move under the force. We propose a learning-from-interaction framework with an online data sampling strategy that allows us to train the network in simulation (SAPIEN) and generalizes across categories.
Bibtex:
@InProceedings{Mo_2021_ICCV,
author = {Mo, Kaichun and Guibas, Leonidas J. and Mukadam, Mustafa and Gupta, Abhinav and Tulsiani, Shubham},
title = {Where2Act: From Pixels to Actions for Articulated 3D Objects},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2021},
pages = {6813-6823}
}
|
 |