|
Bokui Shen, Danfei Xu, Yuke Zhu, Leonidas J. Guibas, Li Fei-Fei, Silvio Savarese. Situational Fusion of Visual Representation for Visual Navigation. Int. Conf. Computer Vision (ICCV), 2019.
Abstract:
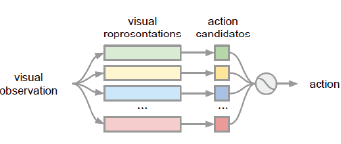
A complex visual navigation task puts an agent in different situations which call for a diverse range of visual perception abilities. For example, to "go to the nearest chair'', the agent might need to identify a chair in a living room using semantics, follow along a hallway using vanishing point cues, and avoid obstacles using depth. Therefore, utilizing the appropriate visual perception abilities based on a situational understanding of the visual environment can empower these navigation models in unseen visual environments. We propose to train an agent to fuse a large set of visual representations that correspond to diverse visual perception abilities. To fully utilize each representation, we develop an action-level representation fusion scheme, which predicts an action candidate from each representation and adaptively consolidate these action candidates into the final action. Furthermore, we employ a data-driven inter-task affinity regularization to reduce redundancies and improve generalization. Our approach leads to a significantly improved performance in novel environments over ImageNet-pretrained baseline and other fusion methods.
Bibtex:
@inproceedings{sxzgls-sfvrvn-iccv19,
Author = {Bokui Shen and Danfei Xu and Yuke Zhu and Leonidas J. Guibas and Li Fei-Fei and Silvio Savarese},
Title = {Situational Fusion of Visual Representation for Visual Navigation},
Booktitle = {Proceedings of the IEEE International Conference on Computer Vision},
Year = {2019}
}
|
 |