We introduce HuMoR: a 3D Human Motion Model for Robust Estimation of temporal pose and shape. Though substantial progress has been made in estimating 3D human motion and shape from dynamic observations, recovering plausible pose sequences in the presence of noise and occlusions remains a challenge. For this purpose, we propose an expressive generative model in the form of a conditional variational autoencoder, which learns a distribution of the change in pose at each step of a motion sequence. Furthermore, we introduce a flexible optimization-based approach that leverages HuMoR as a motion prior to robustly estimate plausible pose and shape from ambiguous observations. Through extensive evaluations, we demonstrate that our model generalizes to diverse motions and body shapes after training on a large motion capture dataset, and enables motion reconstruction from multiple input modalities including 3D keypoints and RGB(-D) videos.
HuMoR: 3D Human Motion Model for Robust Pose Estimation
Rather than describing likely poses, HuMoR models a probability distribution of possible pose transitions,
formulated as a conditional variational autoencoder (CVAE). Though not explicitly physics-based, its components
correspond to a physical model: the latent space can be interpreted as generalized forces, which are inputs to a
dynamics model with numerical integration (the decoder). Moreover, ground contacts are explicitly predicted and used
to constrain pose estimation at test time.
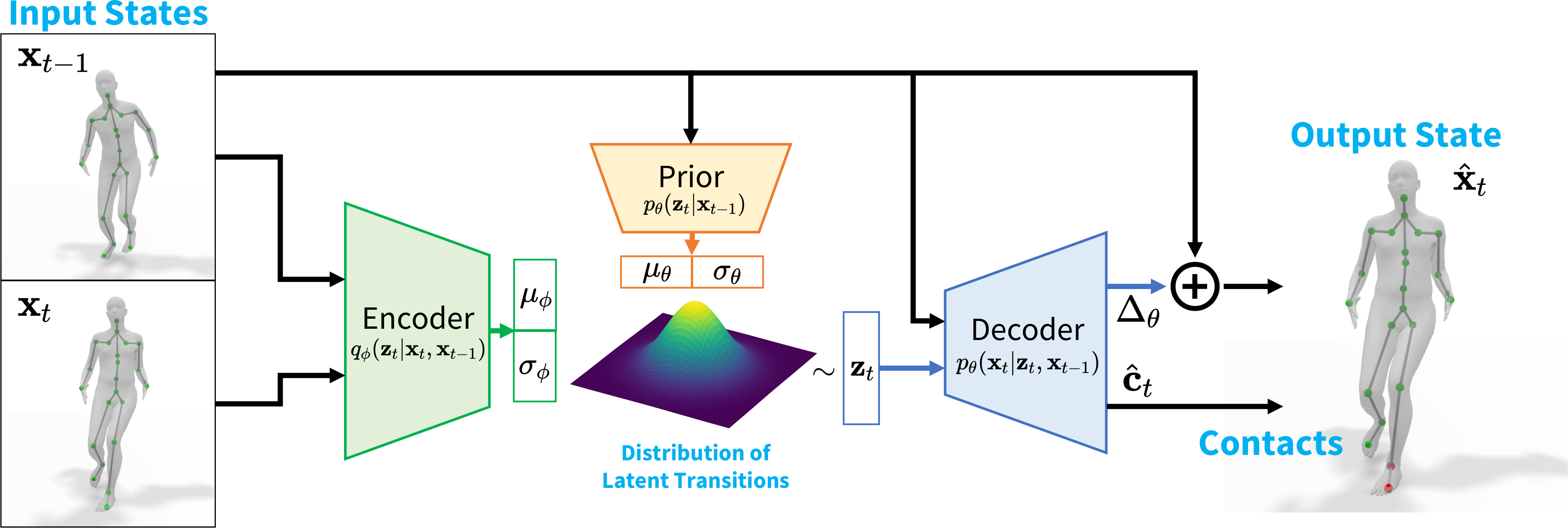
HuMoR conditional variational autoencoder architecture.
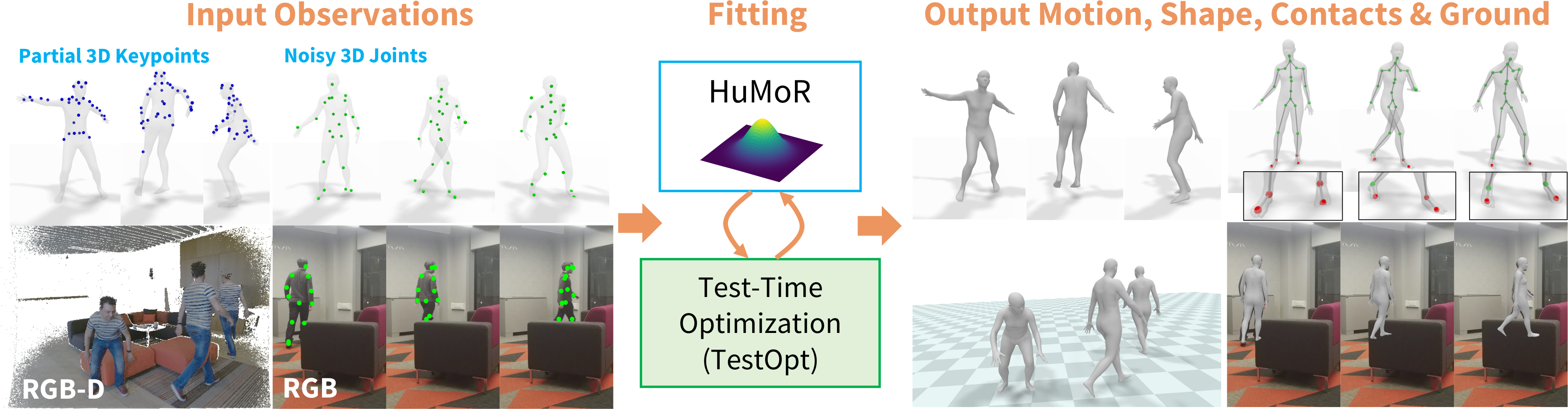
Our optimization procedure leverages HuMoR to recover plausible motions from many modalities even under noise and occlusions.
HuMoR also generalizes to fast and dynamic motions like dancing shown below. See additional dancing results here.
This project page template is based on this page.
@inproceedings{rempe2021humor,
author={Rempe, Davis and Birdal, Tolga and Hertzmann, Aaron and Yang, Jimei and Sridhar, Srinath and Guibas, Leonidas J.},
title={HuMoR: 3D Human Motion Model for Robust Pose Estimation},
booktitle={International Conference on Computer Vision (ICCV)},
year={2021}
}