Overview
TIDE is a benchmark dataset suitable for fine-grained semi-supervised object recognition collected from public Flickr images. The first release of the dataset in June 2012 contained 100K images of 15 objects. he second release in June 2013, is more than twice as large with approximately 214K images of 23 objects. Each object is provided with 200 bound-box annotated instances and an estimated 1000 unsupervised instances per object.

The need for TIDE
Measuring the performance of a semi-superivsed method for fine-grained object recognition requires a ground-truth dataset with some key properites. First it must have fine-grained labels that correspond to specific objects rather than classes of objects. Furthermore it must have a sufficient number and diversity of instances to sufficiently sample the underlying object-manifold such that it coveres the diversity of apperances of the object in the real-world. The TIDE dataset is a new dataset collected for this purpose. Next we show how TIDE is superior to existing datasets for fine-grains tasks that require large semi-supervised training sets.Specificity
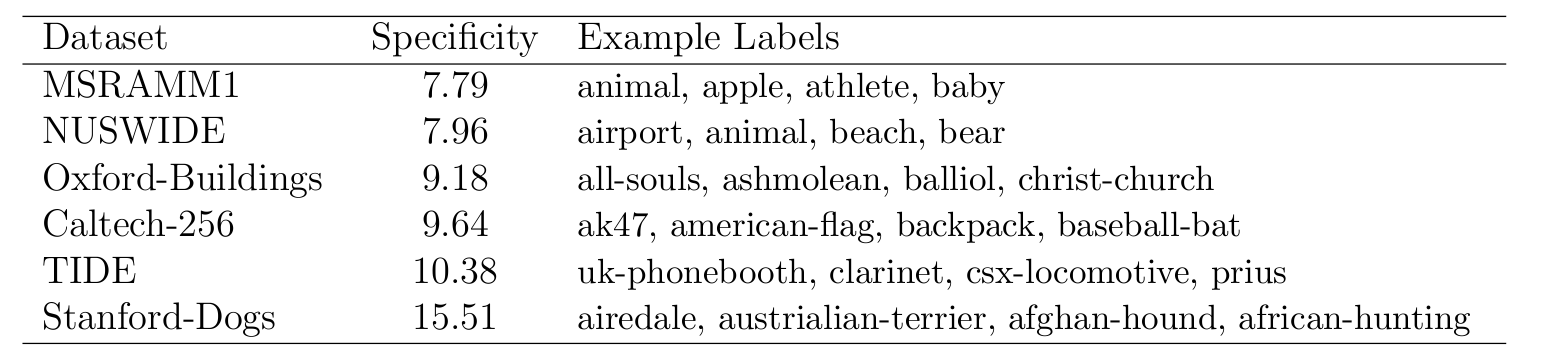
To evaluate the specificity of dataset labels, we propose a simple metric based on the average depth of the labels in the WordNet ontology. Intuitively, datasets with more specific labels will have a larger average wordnet depth. The table below shows popular vision datasets sorted by increasing specificity. Note that the MSRAMM dataset with generic label ``animal'' and ``athlete" has a much lower specificity score than Stanford Dogs dataset with specifc dog breed labels like ``airedale'' and ``austrialian terrier''. Considering representative datasets, we define a dataset as ``fine grained'' if it has an average wordnet depth greater or equal to that of oxfordbuildings.
Size
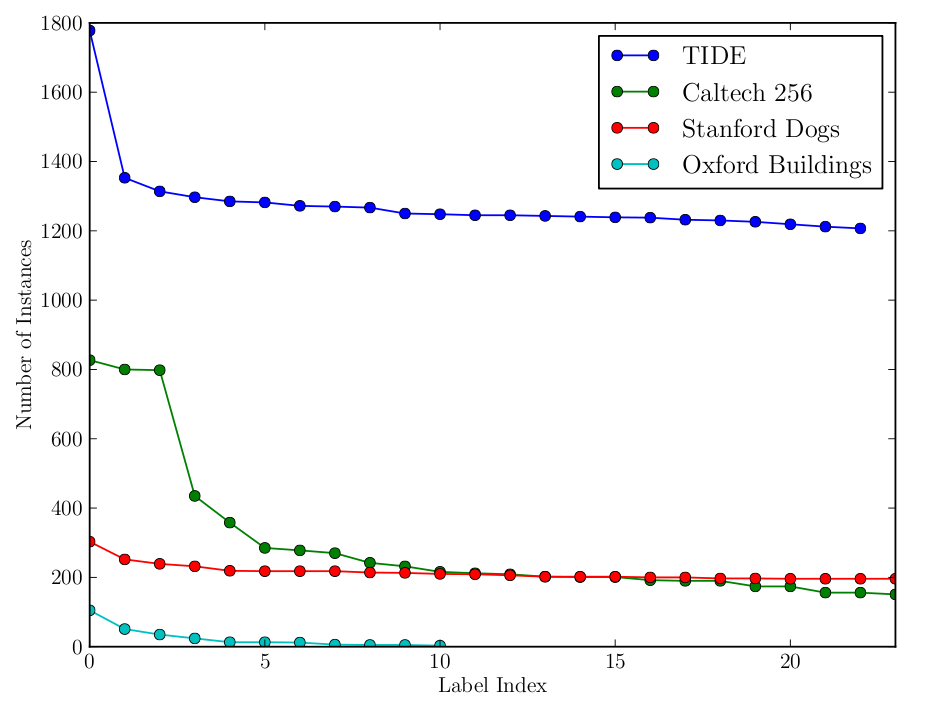
In order to evaluate the performance of a semi-supervised technique, we need a enough examples images for each label type to sufficiently sample the space of object apperances. Emperically, the local feature matching technique may require a thousand instances to form a well connected model of an object viewed from many viewpoints. As shown in the plot below, among existing datasets that have ``finegrained labels'', none have more than 300 examples for all labels. This is clearly insufficient. The TIDE dataset is the only one with a number of examples suitable for evaluating the propsed semi-supervised annotation method using local-feature matching.
Properties of TIDE
The TIDE dataset was collected from flickr images and has the following properties:
- Specific - Each label corresponds to a specific object rather than a class of objects (avg wordnet depth > 10)
- Large - Each label has at least 200 supervised positive instances and at least 1000 positive unsupervised examples
- Validated - Each supervised positive instance is provided with a bounding box verified by at least two labelers
- Representative - The 200 supervised positive images each come from a different Flickr user. This ensures the ground truth represents a representative sample of apperances and that no single user's photos can visually define the object.
The average ground truth image for each of the 23 objects are shown below. Average images are a huristic proposed by for visually summarizing the diversity of apperances and thus the degree of difficulty of a dataset. Datasets in which the average image looks like the object is a sign that the dataset lacks real-world diversity.
